
外观
概率论
Part 1 基本公式
· 随机事件
(1) 随机试验: 在概率论中将具备下列三个条件的试验称为随机试验,简称试验:
在相同条件下可重复进行;
每次试验的结果具有多种可能性;
在每次试验之前不能准确预言该次试验将出现何种结果,但是所有结果明确可知。
(2) 样本空间: 随机试验的所有可能结果构成的集合,常用 Ω 表示。
(3) 随机事件: 随机试验的每一种可能的结果称为随机事件,常用 A, B, C, D 表示。
(4) 基本事件: 不能分解为其他事件组合的最简单的随机事件。
(5) 必然事件: 每次试验中一定发生的事件,常用 Ω 表示。
(6) 不可能事件: 每次试验中一定不发生的事件,常用 表示。
/Definition/
事件的关系及运算:
(1) 包含: 若 发生必然导致 发生,则称 包含于 $$B$$,记为
(2) 相等: 若 且 ,则称 与 相等,记为
(3) 事件的和: A 与 B 至少有一个发生,称为 A 与 B 的和事件,记为
(4) 事件的积: A 与 B 同时发生,称为 A 与 B 的积事件,记为 (或 AB)
(5) 事件的差: A 发生而 B 不发生,称为 A 与 B 的差事件,记为
(6) 互斥事件: 在试验中,若事件 A 与 B 不能同时发生,即 ,则称 A, B 为互斥事件,或互不相容事件。
(7) 对立事件: 在每次试验中,“事件 A 不发生”的事件称为事件 A 的对立事件或逆事件。A 的对立事件常记为 。
· 概率定义
高中阶段我们接触过概率的统计学定义:
在相同的条件下,重复进行 次试验,事件 发生的频率稳定在某一常数 附近摆动,且一般说来, 越大,摆动幅度越小,则称常数 为事件 的概率,记为 .
下面我们尝试将概率公理化:
设 Ω 是一样本空间,称满足下列三条公理的集函数 为定义在 Ω 上的概率:
非负性:任何事件的概率都不是负数,。
可加性:如果事件、、、互斥,则
归一性:整个样本空间也被称为必然事件,它的概率为 ,。
· 运算性质
(1) 加法律
加法公式还能推广到多个事件的情况,例如,设 为任意三个事件,则有
一般地,对于任意 n 个事件 ,有
(2) 减法律
(3) 结合律
(4) 分配律
(5) 补集定律(德摩根定律)
(只要不同时在A,B里就行)可推广:
(既不能在A里也不能在B里)可推广:
· 条件概率公式
公式:
或等价形式
拓展(多事件链式公式): 对于事件序列 :
· 贝叶斯公式
若 构成完备事件组(两两互斥且并集为样本空间),则:
全概率公式:
贝叶斯公式:
事件 和 如果发生的因果关系极小(互不影响),则称 与 为独立事件。
此时满足: 概率乘法公式:
条件概率等价表述:
· 古典概型
样本空间由 个等可能的基本事件构成,具有下列两个特点的试验称为古典概型:
(1) 每次试验只有有限种可能的试验结果。
(2) 每次试验中,各基本事件出现的可能性完全相同。
对于古典概型,事件 A 发生的概率为
· 几何概型
如果随机试验的样本空间是一个区域(例如直线上的区间、平面或空间中的区域),而且样本空间中每个试验结果的出现具有等可能性,那么规定事件 A 的概率为:
· 事件独立性
如果事件 A 发生的可能性不受事件 B 发生与否的影响,也就是 ,则称事件 A 对于事件 B 独立。若 A 对于 B 独立,则 B 对于 A 也独立,那么就称事件 A 与事件 B 相互独立。
基本性质:
(1) A 与 B 相互独立 。
(2) 若 A 与 B 相互独立,则 中的每一对事件都相互独立。
针对 个事件相互独立: 个事件 中任意一个事件发生的可能性都不受其他一个或多个事件发生与否的影响,则称 相互独立。
基本性质:
(1) 如果事件 相互独立,则对于任意 和任意 , 成立。
(2) 如果事件 相互独立,则将 中任意多个事件换成它们的逆事件,所得的 个事件仍相互独立。
(3) 如果事件 相互独立,则
· 重复独立试验
在 次试验中,若任意一次试验的诸结果是相互独立的,则称这 次试验为重复独立试验或独立试验序列。
(1) 伯努利概型:假定一次试验中只有事件 发生或 发生,每次试验的结果与其他各次试验结果无关,这样的 次重复试验称为 重伯努利试验或伯努利概型。
(2) 二项概率公式:设一次试验中事件 发生的概率为 ,则在 重伯努利试验中,事件 恰好发生 次的概率为 , ,其中 。
Part 2 一维随机变量
· 随机变量
看下面几个例子:
(1) 掷骰子:掷一次普通的六面骰子,将出现的点数记为𝑐。
(2) 投硬币:投掷 100 次硬币,统计正面出现的次数,记为𝑎。
(3) 班级人数:在一个学校里随机选择一个班级,将学生人数记为𝑛。
(4) 身高:测量一群人的身高,将结果记为ℎ。
(5) 重量:记录某个产品的质量,将结果记为𝑚。
(6) 时间:记录一个运动员跑 100 米的时间为𝑡。
随机变量是实验结果的实值函数:将实验结果与某个实数绑定。
而随机变量可根据分布特点划为两种情况:离散随机变量和连续随机变量。
除了一维变量,还常见二维变量,比如:
(1) 考试成绩:将学生的英语分数𝑎和数学分数𝑏记录为一个二维数据(𝑎, 𝑏)。
(2) 温度湿度:将城市中一天内的平均温度𝑇与湿度𝑊记录为一个二维数据(𝑇, 𝑊)。
· 定义
设 E 是一个随机试验,其样本空间为 ,如果对于每一个样本点 ,都有唯一的一个实数 与之对应,则称 为一维随机变量。通常用 表示随机变量。
分布函数
设 是一个随机变量, 是任意实数,则函数 称为 的分布函数。
(1) 单调性: 是一个单调不减的函数,即当 时,。
(2) 有界性: ,且
(3) 右连续性: ,即 是右连续函数。
由分布函数求概率
· 一维离散变量
· 0-1分布
其分布律为
| X | 0 | 1 |
|---|---|---|
| P | p | 1-p |
其中 为事件 出现的概率, 。
· 二项分布
若实验仅有两种结果 和 ,且 。将该实验独立重复 次,事件 发生的次数 服从二项分布,
其概率分布律为:
记法:
· 泊松分布
当二项分布中 且 时,可用泊松分布近似,其概率公式为:
记法:
拓展知识:当𝝀越来越大时,泊松分布曲线越发接近正态分布。
关于泊松分布的由来:
当二项分布 满足 且记 时:
通过泰勒展开式验证所有概率之和为1:
概率求和:
· 超几何分布
设随机变量 的分布律是
其中 都是自然数,且 ,则称 服从参数为 的超几何分布,记作 。
· 几何分布
设随机变量 的分布律为
其中 ,则称 服从参数为 的几何分布,记为 。
· 一维连续变量
设想以下几种情况:
(1) 让一辆车随机停在街边的某个位置,坐标记为 。
(2) 一个运动员跑 100 米所需的时间,记为 。
如何描述随机变量 和 的取值情况?需要认识什么是概率密度函数。
设 是一个连续随机变量, 是任意实数:
概率密度函数 (PDF)
概率分布函数 (CDF)
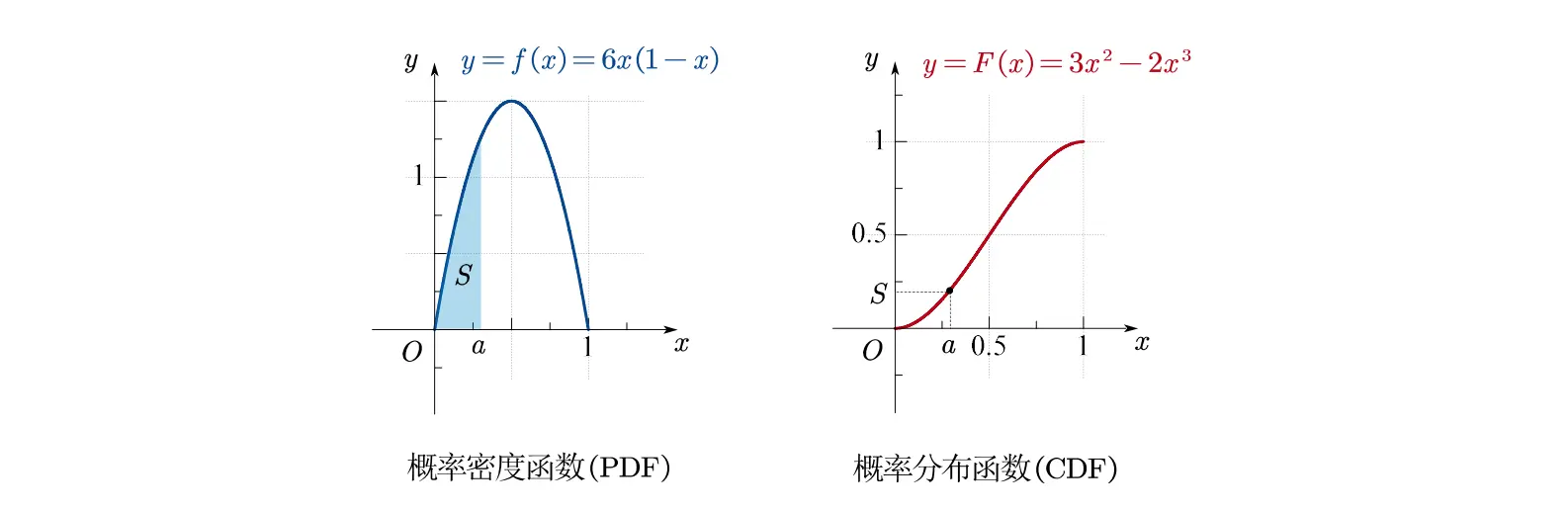
| 特性 | 密度函数 | 分布函数 |
|---|---|---|
| 两端 | ||
| 单调性 | 不一定 | 单调递增 |
| 阴影面积 | 不一定 | |
| 应用场景 | 关注特定区间的概率情况 | 关注左侧 () 的整体累积情况 |
| 关联 |
· 均匀分布
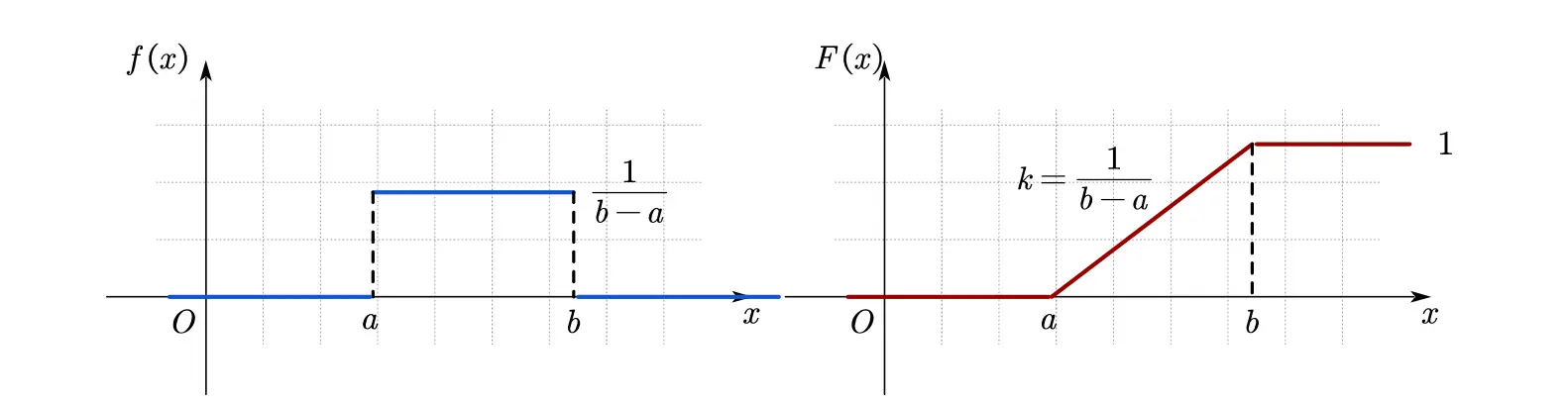
概率密度函数 (PDF):
概率分布函数 (CDF):
期望:
方差:
· 正态分布
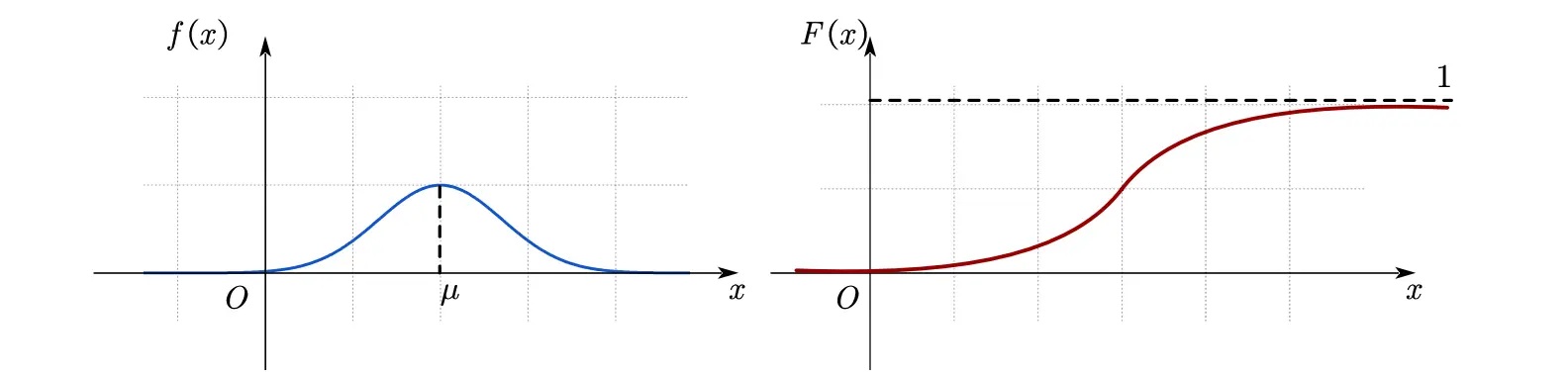
概率密度函数 (PDF):
概率分布函数 (CDF):
期望: 方差: .
标准正态分布:当 时称 服从标准正态分布,简记为 ,其概率密度函数和分布函数分别用 表示,即有
性质 1
性质 2 :当 时, ,即
可把一般正态分布化为标准正态分布
· 指数分布
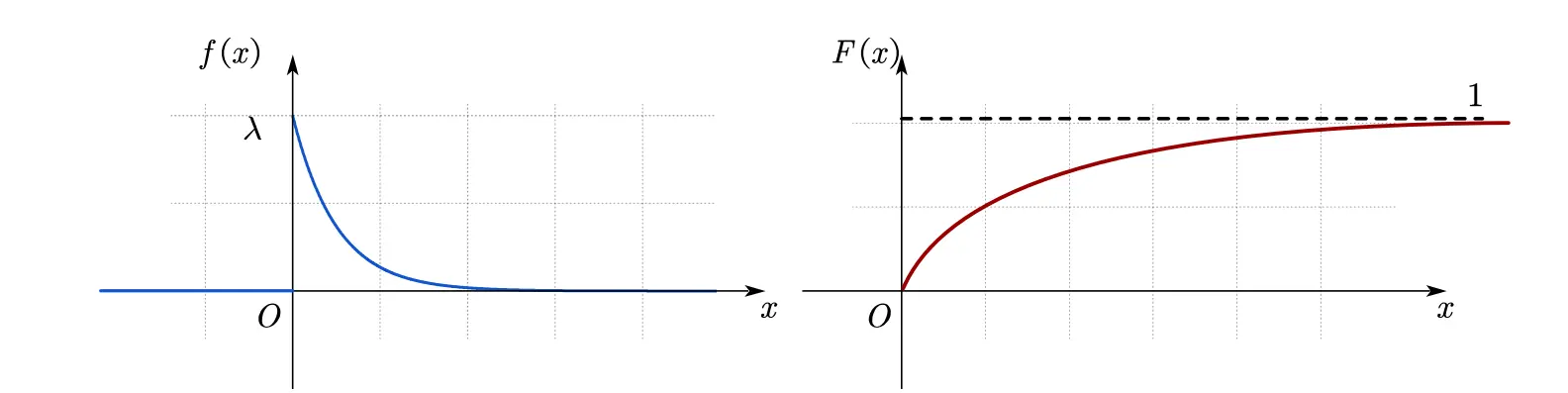
概率密度函数 (PDF):
概率分布函数 (CDF):
期望:
方差:
· 随机变量函数分布
(1). 离散型随机变量函数的分布
设随机变量 的分布律为 ,则当 的所有取值为 时,随机变量 有分布律
(2). 连续型随机变量函数的分布
方法一:设随机变量 的概率密度函数为 ,那么 的分布函数为
其概率密度为 。
方法二:设随机变量 具有概率密度函数 , 为 内严格单调的可导函数,则随机变量 的概率密度为
其中 是 的反函数,
· 例题
设随机变量的概率密度函数如下:
(1) 的概率密度函数。 (2) 的概率密度函数。 (3) 的概率密度函数。
(1) 第一步:求的分布函数
第二步:求的概率密度函数
第三步:代入中:
(2) 第一步:求的分布函数
第二步:求的概率密度函数
第三步:代入中:
(3) 第一步:求的分布函数
第二步:求的概率密度函数
第三步:代入中:
Part 3 二维随机变量
· 二维连续变量
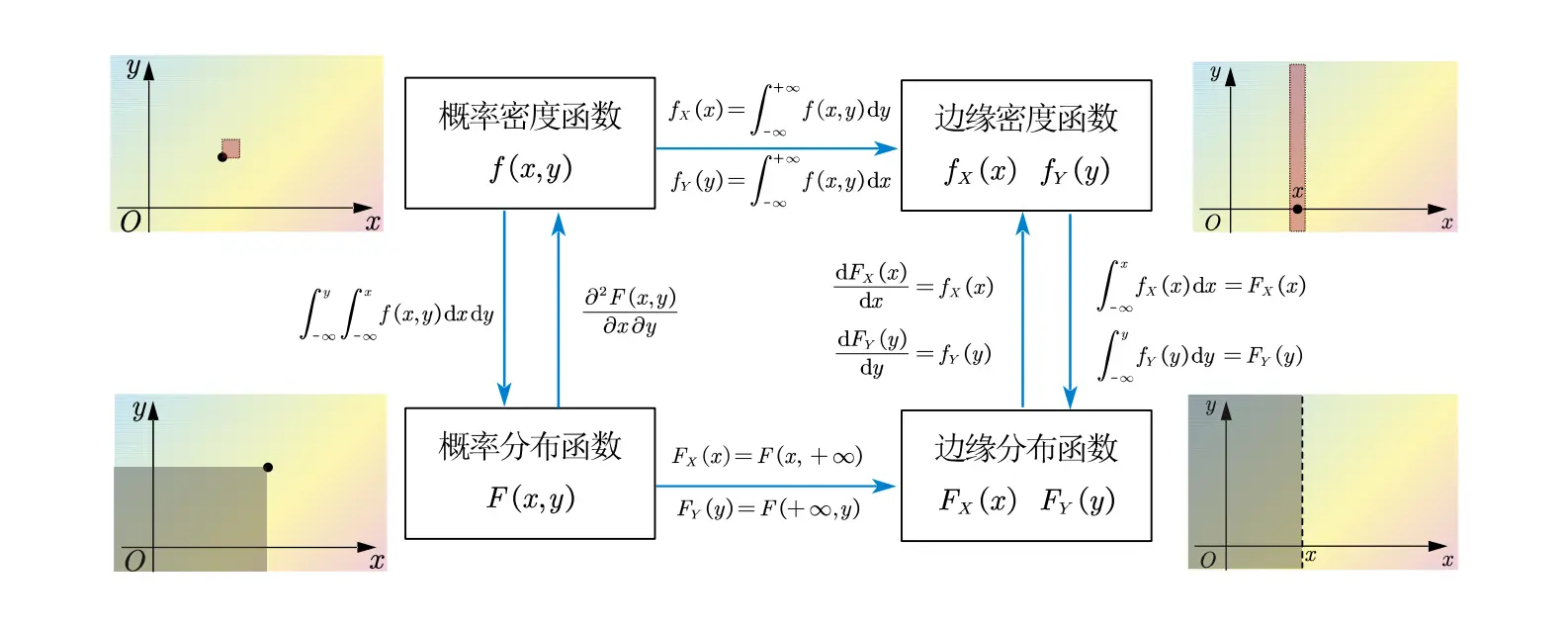
二维连续随机变量 的联合概率密度函数 :
二维连续随机变量的联合概率分布函数:
概率密度与概率分布之间的关系:
边缘概率密度函数、:
边缘概率分布函数、:
彼此关联:
· 相互独立性
在二维随机变量 中,如果 和 相互独立,则有以下等式成立:
这两个式子也可以用来判断两个变量是否相互独立。
· 二维连续变量的函数
设 是二维连续随机变量,其联合概率密度为 ,则随机变量 的常见函数形式包括:
- 和函数:
- 商函数:
- 积函数:
- 最大值函数:
- 最小值函数:
对于上述任意函数形式,求 的概率分布函数 或概率密度函数 的步骤如下:
(1) 确定取值范围
根据 的联合分布范围,确定 的有效取值区间:
(2) 建立积分区域
在 平面中,绘制不等式 对应的区域 :
其中 表示 与 的函数关系式
(3) 计算分布函数
通过二重积分求概率:
(4) 求导得密度函数
对分布函数求导获得概率密度:
Part 4 随机变量的数字特征
· 期望 方差
· 期望
/Definition/
(1). 离散随机变量
(2). 一维连续随机变量
(3). 二维连续随机变量
数学期望的性质:
(1). 线性性质
(2). 可加性
(3). 独立性:若 独立,则
· 方差
/Definition/
方差 :衡量随机变量的分散程度
(1). 离散随机变量
(2). 一维连续随机变量
方差的性质:
(1). 线性变换
(2). 可加性
若 独立,则 .
(3). 简化计算
(4). 标准差
| 分布 | 期望 | 方差 |
|---|---|---|
| 二项分布 | ||
| 泊松分布 | ||
| 均匀分布 | ||
| 正态分布 | ||
| 指数分布 |
· 协方差
被称为随机变量 的协方差,记为 。
(1).
其中是常数
(2).
(3). 协方差的公式还可以等价于:
基于协方差,还会产生一个概念:相关系数
的取值介于 之间,其越接近0说明两者线性相关性越低(,则称两变量不相关),绝对值越大则越呈线性相关(-1则是负相关,+1是正相关)。
注意:两变量不相关 两变量独立,不相关不一定独立,但独立一定不相关。
· 随机变量的矩
一维随机变量的矩:对于一维随机变量 :
k阶原点矩:
k阶中心矩:
特殊情形:
- 数学期望 是 的一阶原点矩
- 方差 是 的二阶中心矩
二维随机变量的混合矩:设 是二维随机变量:
k+l阶混合原点矩:
k+l阶混合中心矩:
重要结论:协方差 是 与 的混合二阶中心矩。
Part 5 大数定理与中心极限定理
· 切比雪夫不等式
设随机变量 的期望为 ,方差为 ,则对于任意给定的 ,有:
或等价地
说明:
- 该不等式给出了随机变量偏离期望值的概率上界
- 方差 越小,偏离概率的上界越小
- 适用于任何具有有限方差的随机变量
· 大数定律
大数定理:在大量重复试验中,样本平均数会趋近于理论期望值。换句话说,当试验次数足够多时,实验结果的平均值会接近预期的长期平均值。
切比雪夫大数定律 (Chebyshev's LLN).
条件:
- 随机变量序列 相互独立
- 数学期望 和方差 都存在
- 方差有公共上界: ()
结论: 对任意 ,有
核心思想: "只要方差有限,大量重复试验的平均值会接近期望值"
伯努利大数定律 (Bernoulli's LLN).
条件: 设 , 是 次伯努利试验中事件 发生的次数
结论: 对任意 ,有
核心思想: "投硬币这类事情,大量地实验结果里,频率会接近概率"
辛钦大数定律 (Khinchin's LLN).
条件: 随机变量序列 相互独立同分布,且
结论: 对任意 ,有
核心思想: "同一类型的随机变量,大量样本的平均值会接近期望值"
· 中心极限定理
个随机变量,它们相互独立且服从同一种分布规律(独立同分布),期望值为,方差为,有:
概率部分结束.
更新日志
2025/10/12 15:13
查看所有更新日志
c9ee8-于a8b03-于a28aa-于