
外观
数理统计
Part 1 数理统计基本概念
样本统计量定义:从总体中抽出n个独立同分布的个体 , , , ,记为样本(样本容量为n)。
样本均值:
样本方差:
样本标准差:
样本k阶原点矩:
样本k阶中心矩:
经验分布函数定义:设 , , , 是来自总体X的一个样本,将样本观测值按从小到大的顺序排列为 。经验分布函数 定义为:
· 三大抽样分布
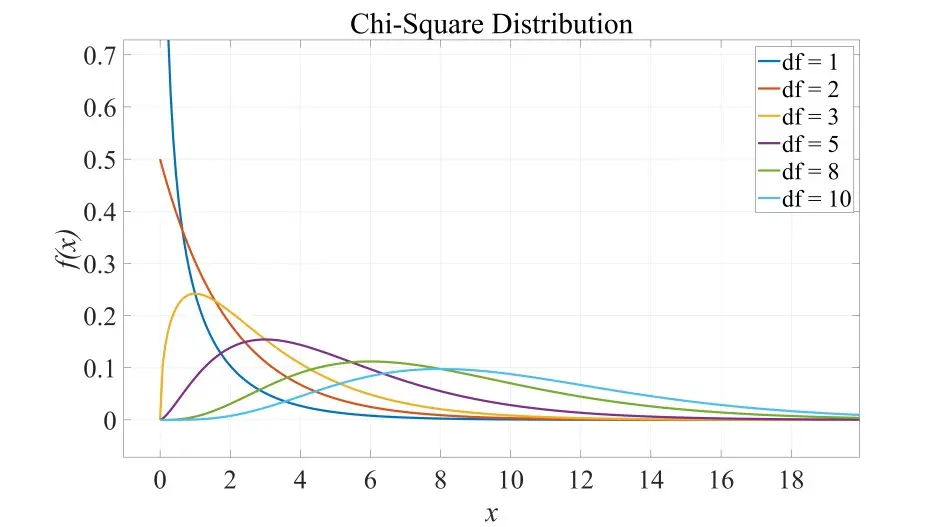
**卡方分布 (Chi-square Distribution) **
条件要求:各分量 且相互独立,自由度为 .
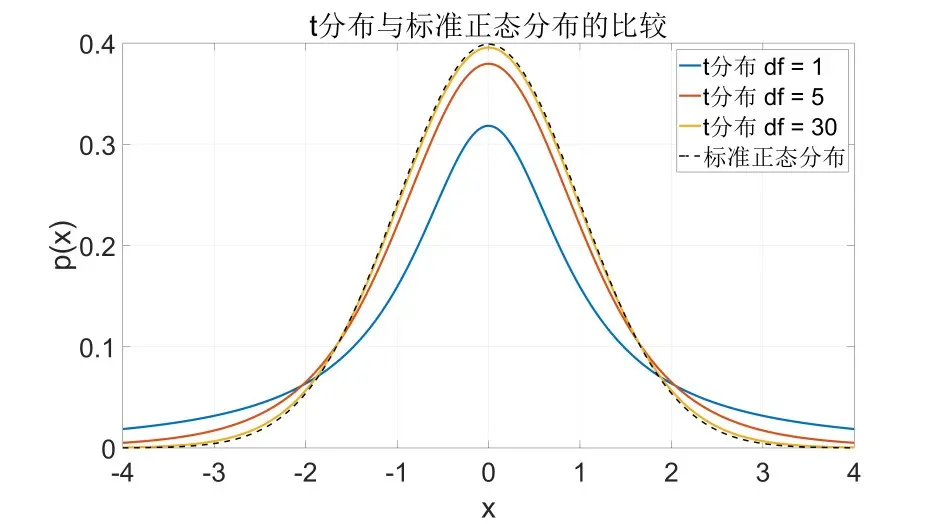
t分布 (Student's t-Distribution)
条件要求:分子 ,分母 ,自由度为 .
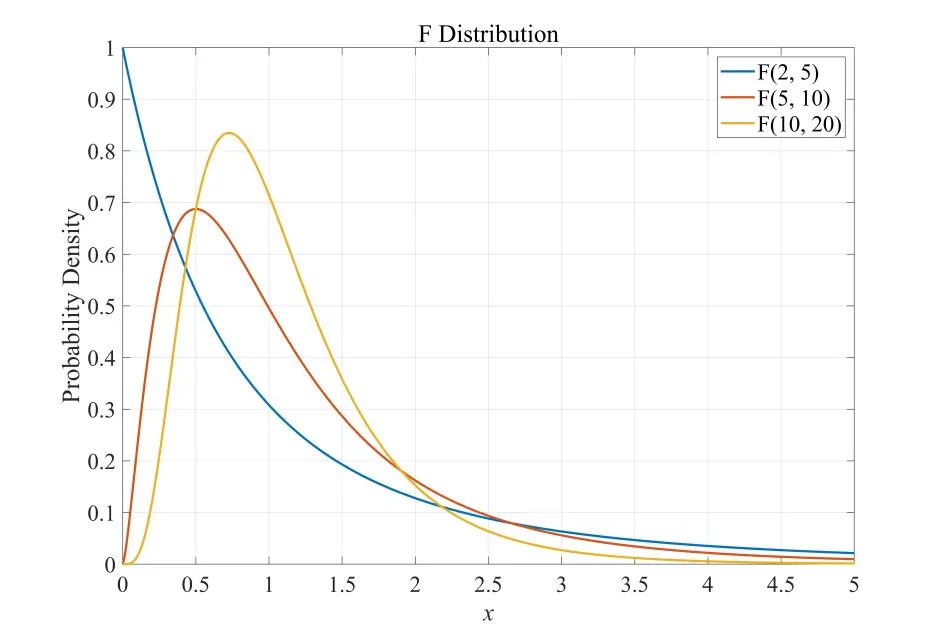
F分布 (F-Distribution)
条件要求:分子 ,分母 ,自由度分别为 和 .
/Definition/
分位数定义:对于遵循某个分布的随机变量 ,给定一个参数 ,如果存在一个值满足:
则称 为该分布的上 分位点。
不同分布的上 α 分位点表示
卡方分布:上 分位点记为 .
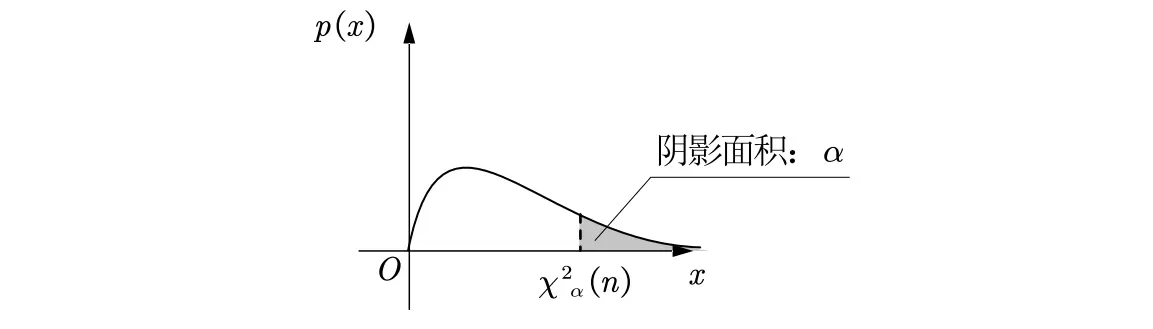
t分布:上 分位点记为 .
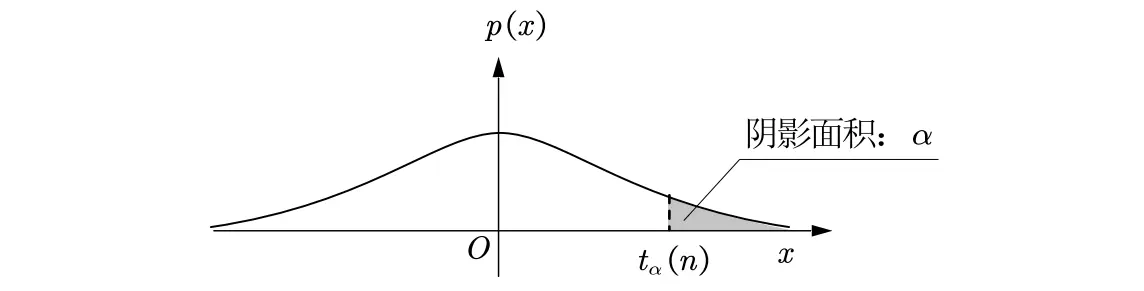
F分布:上 分位点记为 .
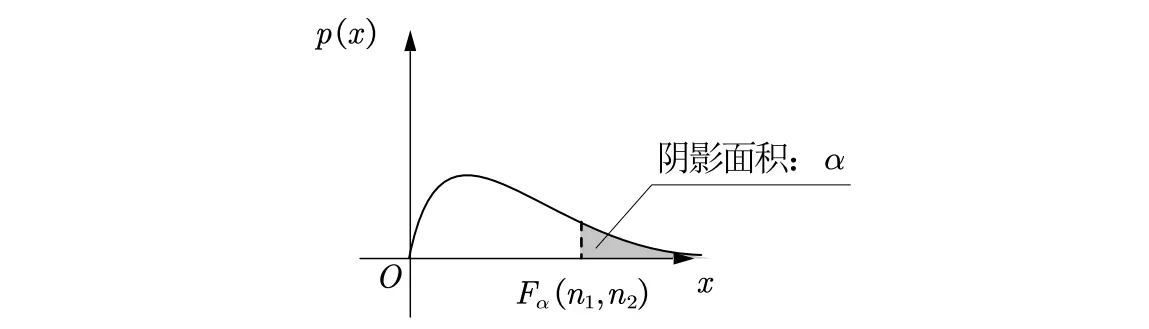
· 样本均值与样本方差分布
单个正态总体
设总体 , 是来自总体 的简单随机样本,定义:
- 样本均值:
- 样本方差:
(1) 样本均值的分布
标准化样本均值(已知总体方差 ):
t分布形式(未知总体方差,用样本方差 替代):
(2) 样本方差的分布
总体均值已知时:
总体均值未知时(用样本均值 替代):
Part 2 参数估计与假设检验
我们需要用有限的样本数,来估算总体的状况。具体来说就是估计总体的实际平均值(有时候也估计总体的方差),而这里的“估计”又分为两类:
(1)估算实际平均值(例一);
(2)估算实际平均值会在哪个范围内(例二)。
前者我们称之为“点估计”,后者则是“区间估计”
· 点估计
矩估计:样本矩与总体矩相等。
第一步:如果要估计𝑛个参数,需要计算总体以及样本中的前𝑛阶原点矩;
第二步:样本矩=总体矩,得到𝑛个方程,可解出𝑛个参数的估计值;
最大似然估计:让参数取“最有可能”的值。
第一步:按照样本取值,写出对应“取得该值的概率”,即样本的似然函数;
第二步:令似然函数取得最大值,求得此时对应的参数值作为估计值。
· 习题
/example/ 设 为总体 的一个样本,求下列概率密度中未知参数 的矩估计量和最大似然估计量。
概率密度函数:
其中 。
[矩估计].
计算总体期望:
解得 与 的关系:
用样本均值 代替 ,得到矩估计量:
[最大似然估计].
构建似然函数:
取对数似然函数:
对 求导并令导数为零:
解得最大似然估计量:
/example/
概率密度函数:
其中 。
[矩估计].
计算总体期望:
解得 与 的关系:
用样本均值 代替 ,得到矩估计量:
[最大似然估计].
构建似然函数:
取对数似然函数:
对 求导并令导数为零:
解得最大似然估计量:
· 估计量的评选标准
设 是总体 分布中的待估参数,其估计量为 :
(1). 无偏性:若估计量的期望等于实际参数值,即:
则称 是 的无偏估计量。
(2). 有效性:对于同一参数 的两个无偏估计量 和 ,若满足:
则称 比 更有效。
(方差越小,估计量越稳定,有效性越高)
(3). 一致性(相合性):当样本容量 时,若 依概率收敛于 ,即:
则称 为 的一致估计量。
· 区间估计
(1). 总体方差已知时(已知):
(2). 总体方差未知时(未知):
(3). 总体方差分布:
期望的置信区间
(1). 已知时,置信区间公式:
(2). 未知时,置信区间公式:
符号说明:
- :样本均值
- :样本标准差
- :样本数
- :标准正态分布的上分位点
- :分布(自由度)的上分位点
方差的置信区间
置信区间公式:
符号说明:
- :分布(自由度)的上分位点
- :样本方差
- :样本数
· 假设检验
假设检验的类型与原理,与区间估计的几乎一致。但是以下概念需要清楚:
原假设和备择假设:称需要着重考察的假设为原假设,原假设常记为 ;与原假设相对立的假设称为备择假设或对立假设,备择假设常记为 。
检验统计量:如果基于某一个统计量的观测值来确定接受 或拒绝 时,这一统计量称为检验统计量。
拒绝域和临界点:当检验统计量的观测值落在某个区域时就拒绝 ,这一区域称为拒绝域,拒绝域的边界点称为临界点。
显著性水平 :是一个小的正数,在作检验时要求犯第Ⅰ类错误的概率 , 称为检验的显著性水平。 通常取 0.1, 0.05, 0.01, 0.005 等值。
假设检验的两类错误:
- 实际上为真时,而拒绝 ,这类弃真的错误称为第Ⅰ类错误。
- 实际上为假时,而接受 ,这类取伪的错误称为第Ⅱ类错误。
显著性检验:对于给定的样本容量,只控制犯第Ⅰ类错误的概率,而不考虑犯第Ⅱ类错误的概率的检验法,称为显著性检验。
数理统计部分结束.
更新日志
2025/10/12 15:13
查看所有更新日志
c9ee8-于a28aa-于